Overview
After a post from this site made the front page of Hacker News (HN), a curious quirk was spotted. The first time the post was published on HN was at 2016-06-12 09:27:01.000Z. The second time the same post was published on HN was at 2016-06-15 02:03:36.000Z. Notice that they are only three days apart. The one published on the 12th received only one or two points by the 15th. The repost, published on the 15th, received over 170 points (within hours of being published) and maintained position one for awhile.
In some cases, a piece of content will be posted and then–minutes later–will be posted again where the almost immediate repost will make the front page and the earlier version will forever stay on the back page. In other cases, it can take years before a repost will finally grace the cover of Hacker News. Of course there are pieces of content that get reposted year after year with each repost doing equally well.
To illustrate, here is an example of a piece of content that was posted and then reposted nine times. The ninth time made the front page. The span of time was 122 days, 2 hours, 47 minutes, and 24 seconds.
ID User Score Time Title URL Front Page Story Id
"11540337" "dnetesn" "2" "1461225802" "Why Physics Is Not a Discipline" "http://nautil.us/issue/35/boundaries/why-physics-is-not-a-discipline" "12330360"
"11550152" "dnetesn" "2" "1461341001" "Why Physics Is Not a Discipline" "http://nautil.us/issue/35/boundaries/why-physics-is-not-a-discipline" "12330360"
"11556082" "dnetesn" "2" "1461427428" "Why Physics Is Not a Discipline" "http://nautil.us/issue/35/boundaries/why-physics-is-not-a-discipline" "12330360"
"11562342" "celadevra_" "2" "1461552906" "Why Physics Is Not a Discipline" "http://nautil.us/issue/35/boundaries/why-physics-is-not-a-discipline" "12330360"
"11564691" "feelthepain" "3" "1461597092" "Why Physics Is Not a Discipline" "http://nautil.us/issue/35/boundaries/why-physics-is-not-a-discipline" "12330360"
"11570675" "dnetesn" "1" "1461666275" "Why Physics Is Not a Discipline" "http://nautil.us/issue/35/boundaries/why-physics-is-not-a-discipline" "12330360"
"11578913" "dnetesn" "1" "1461749668" "Why Physics Is Not a Discipline" "http://nautil.us/issue/35/boundaries/why-physics-is-not-a-discipline" "12330360"
"11621763" "dnetesn" "1" "1462291025" "Why Physics Is Not a Discipline" "http://nautil.us/issue/35/boundaries/why-physics-is-not-a-discipline" "12330360"
"11666213" "dnetesn" "1" "1462877056" "Why Physics Is Not a Discipline" "http://nautil.us/issue/35/boundaries/why-physics-is-not-a-discipline" "12330360"
"12330360" "dnetesn" "22" "1471776646" "Physics is not just what happens in the Department of Physics" "http://nautil.us/issue/35/boundaries/why-physics-is-not-a-discipline" "12330360"The following is a look at Hacker News front page stories and their back page counterparts. We will look at how they differ as we search for any patterns that distinguish the two.
Terminology
- HN: Hacker News
- Post: the first time a piece of content is submitted to HN
- Repost: the second to nth time the same piece of content is submitted to HN
- Front candidates: Stories gathered from the front route and HN item API
- Back candidates: Hits gathered from the Algolia search API after querying a front page story’s URL
- Front(s): Front candidates that had one post that never made it to the front page and only one repost that made it to the front page
- Back(s): Back candidates, that when grouped by their related front, had only one repost that made it to the front page
Collection
In order to collect the stories that at one time made the front page, story IDs, usernames, titles, scores, and post dates were indexed from the Hacker News front route. These IDs where then queried against the Hacker News item API where each returned item was stored in a SQLite database.
While there is an API endpoint for top stories, this is only for the top stories right now and is not an explicit confirmation of being on the front page. There is also a best stories API endpoint but it only gives the highest voted recent links. Thus the front route was used to ruled out any kind of ambiguity. Unfortunately, the HN items returned from the items endpoint do not indicate whether or not they made the front page.
To find the back candidates, Algolia search was queried using the front page story URLs.
Overall, 5,746 front candidates were collected along with 4,681 back candidates.
Front
All of the front candidates collected were indexed from the HN front route and verified via the HN items API endpoint. The front candidates’ time stamps ranged from Mon, 27 Jun 2016 20:58:30 GMT to Sat, 03 Sep 2016 16:28:55 GMT. After having collected the back candidates, any front page story that did not retrieve any hits (besides itself) from Algolia was ignored during the analysis.
Hacker News Item
The front page stories collected from the front route did not have all of their information. One of the missing pieces of information was the exact date and time the story was posted. Each ID collected from the front route was queried against the HN items API endpoint. These HN items were saved in their own SQLite database table.
Algolia Hit
To find the back candidates corresponding to the front page stories, the Algolia API was used. For every front page story collected, its cleaned URL was used to search Algolia. The Algolia hits returned were stored in their own SQLite database table which had a foreign key column relating each row to a row in the HN items table. There was a many to one relationship between Algolia hits and HN items.
Pre-processing
Most of the pre-processing centered around evaluating back and front candidates. To find content that was posted and then reposted one or more times, the URL was used. Each URL was broken up into five major parts. Country code top-level domains (ccTLDs) were collapsed to a single top-level domain (TLD).
The following procedure was carried out when comparing a back candidate’s URL to its front candidate’s URL:
- Break the back candidate URL into subdomain, domain sans the TLD, TLD, path, and query
- Break the front candidate URL into subdomain, domain sans the TLD, TLD, path, and query
- When looking at a URL, if it had a path then the query was set to the empty string
- Compute the Levenshtein distance (LD) between
- back candidate subdomain and front candidate subdomain
- back candidate domain sans the TLD and front candidate domain sans the TLD
- back candidate TLD and front candidate TLD
- back candidate path and front candidate path
- back candidate query and front candidate query
- Declare the back candidate a URL match to its front candidate if
- subdomain LD is less than 10 AND
- domain sans the domain LD equals zero AND
- TLD LD equals zero AND
- path LD is less than 2 AND
- query LD equals zero
The following demonstrates some of the cases that were seen:
https://lettier.github.io vs http://lettier.github.io
^ ^
https://lettier.github.io vs http://lettier.github.io/index.html
^ ^ ^ ^^^^^^^^^^^
https://lettier.github.io? vs http://lettier.github.io/index.html
^ ^ ^ ^^^^^^^^^^^
https://www.lettier.com vs http://lettier.com
^ ^^^^ ^ ^
https://www.bbc.co.uk vs https://www.bbc.com
^^^^^ ^^^Every potential URL match was reviewed for correctness along with the potential mismatches.
Front and Back Criteria
The following criteria was used to confirm an Algolia hit (back candidate) as a back:
- Does not have the same ID as any front page story
- Has a URL
- Has an equivalent URL to its related front page story
- Was posted before its related front page story
- Given a front page story and its Algolia Hits (besides itself), there exists no Algolia hit with four or more points
- It has three or less points
This criteria was necessary to pull out all examples of some piece of content being posted and then reposted until it finally reached the front page.
Back -> Back -> Back -> ... => Front
Post -> Repost -> Repost -> ... => Repost
<---------------- Time ----------------->The three or less points was a criteria as four was the minimum number of points observed for front candidates that had related back candidates.
Fronts were defined as having a matching ID in the backs’ collection of foreign key front page story IDs. Note that no two front page stories, HN items, or Algolia hits had the same ID. Within each database table, all row primary key IDs were unique.
Analysis
Analysis of HN content typically only focuses on what made the front page and when. Rarely do you see an analysis of what did not make the front page. Given the exact same piece of content (news, blog post, software project, etc.), why does an early submission never reach the front page while a later resubmission does? By comparing pieces of content that were posted and then reposted, with only one repost making the front page, we can search for discernible patterns alluding to what makes a piece of content a front page HN story.
The analysis consisted of comparing 425 fronts against 570 corresponding backs. Facets looked at were day of the week, time of day, title word usage, title sentiment, vectorized title projections, and users.
To ease the analysis, all of the fronts and their backs were indexed into Elasticsearch. Fronts were indexed as parent documents with their related backs being indexed as child documents.
Date and Time
One possibility of a why a front succeeded versus its backs may be due to the day of the week and/or the time of the day it was reposted. Does knowing when a story was reposted tell you something about it either reaching the front page or staying on the back page? Is date and time independent from front vs back?
Note that all time stamps were converted to EDT from GMT.
Day of the Week
Using Elasticsearch to aggregate by day of the week, we analyze the relative frequency of fronts versus backs.

Day of the Week
You can see very little relative difference for Monday. The largest relative differences can be see on Saturday and Sunday–the weekend.

Day of the Week Difference
In this chart we explicitly visualize absolute value difference between the relative frequencies. There is a large difference on Tuesday with there being more relative backs than fronts. After Tuesday, the difference goes down the next day and slowly grows until Sunday. There were more backs observed on Wednesday, Thursday, and Friday. Saturday and Sunday, however, has more fronts than backs observed.
Having two nominal categories–day of the week and page status–we can use the Chi-Square test of independence.
Assumptions of the Chi-Square test of independence are:
- The data is frequencies or counts
- The category levels are mutually exclusive (a HN submission can not have two timestamps or be both a front and a back at the same time)
- Each subject (HN submission) can only contribute data to one cell in the contingency table (an HN submission cannot be both
(Monday, Front)and(Tuesday, Back)for example) - The expected values in each cell are 5 or more in 80% of the cells
| | Mon | Tue | Wed | Thur | Fri | Sat | Sun | Totals |
|-------|------------|------------|------------|------------|------------|------------|------------|--------|
| Back | 85 (87.08) | 97 (78.48) | 99 (96.24) | 97 (88.79) | 95 (86.50) | 50 (67.03) | 47 (65.88) | 570 |
| Front | 67 (64.92) | 40 (58.52) | 69 (71.76) | 58 (66.21) | 56 (64.50) | 67 (49.97) | 68 (49.12) | 425 |
| | 152 | 137 | 168 | 155 | 151 | 117 | 115 | 995 |
Expected values shown in parentheses.
Null Hypothesis = H0 = Page Status (Front vs Back) and Day of the Week are independent
Alternative Hypothesis = H1 = Page Status (Front vs Back) and Day of the Week are dependent
P(Type I Error) = alpha = a = 0.05
Chi-Square statistic = 37.050859063487195
Degrees of Freedom = 6
Cramer's V = 0.19296902415909076
P(Chi-Square statistic >= observed | H0) = p-value < 0.0001
Reject H0.Based on the p-value being less than the alpha value, the data supports the alternative hypothesis. However, based on the Cramer’s V, the strength of the association is weak.
Time of Day
Separating out the time of day from their time stamps, we visualize the relative frequencies of backs versus fronts.

Time of Day

Time of Day
Looking at the chart, 0600 and 1100 immediately stand out. However, are these observed differences just chance occurrences because of the sample we took?
| | 0000 | 0100 | 0200 | 0300 | 0400 | 0500 | 0600 | 0700 | 0800 | 0900 | 1000 | 1100 | 1200 | 1300 | 1400 | 1500 | 1600 | 1700 | 1800 | 1900 | 2000 | 2100 | 2200 | 2300 | Totals |
|-------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|------------|--------|
| Back | 16 (14.89) | 17 (15.47) | 18 (14.89) | 15 (14.89) | 21 (24.63) | 21 (22.91) | 15 (22.91) | 21 (22.91) | 20 (24.06) | 31 (32.08) | 41 (38.38) | 23 (32.65) | 31 (30.36) | 41 (36.66) | 33 (31.51) | 42 (42.39) | 33 (28.64) | 27 (23.49) | 15 (13.75) | 20 (20.62) | 17 (15.47) | 17 (14.89) | 21 (17.19) | 14 (14.32) | 570 |
| Front | 10 (11.11) | 10 (11.53) | 8 (11.11) | 11 (11.11) | 22 (18.37) | 19 (17.09) | 25 (17.09) | 19 (17.09) | 22 (17.94) | 25 (23.92) | 26 (28.62) | 34 (24.35) | 22 (22.64) | 23 (27.34) | 22 (23.49) | 32 (31.61) | 17 (21.36) | 14 (17.51) | 9 (10.25) | 16 (15.38) | 10 (11.53) | 9 (11.11) | 9 (12.81) | 11 (10.68) | 425 |
| | 26 | 27 | 26 | 26 | 43 | 40 | 40 | 40 | 42 | 56 | 67 | 57 | 53 | 64 | 55 | 74 | 50 | 41 | 24 | 36 | 27 | 26 | 30 | 25 | 995 |
Expected values shown in parentheses.
Null Hypothesis = H0 = Page Status (Front vs Back) and Time of Day are independent
Alternative Hypothesis = H1 = Page Status (Front vs Back) and Time of Day are dependent
P(Type I Error) = alpha = a = 0.05
Chi-Square statistic = 26.806877906649206
Degrees of Freedom = 23
Cramer's V = 0.1641389223670862
P(Chi-Square statistic >= observed | H0) = p-value < 0.2643
Fail to reject H0.Because the p-value is greater than the alpha value, we fail to reject the null hypothesis that the two nominal categories are independent.
Title
With the way in which HN is laid out, the title is all one has to go on while scanning stories on the new page. Is the title the defining factor between falling off the new page, never to be seen again, or making a giant splash on the front page?
Out of the 570 backs, 200 had the exact same title as their related front.
Word Usage
Using Elasticsearch’s inverted index and English analyzer, we can easily aggregate the title word usage frequencies for both fronts and backs.

Title Word Relative Frequency
Here is the top of the chart. The full version can be found here (1.3 MB).
{kind=link}
PDF was the most frequent for backs and fronts with it usually being seen in the title as ... ... [pdf]. Looking over the rest of the chart, there is not any clear differences between fronts and backs. If you look at show and hn, a collocation, they are slightly more frequent for fronts.
Sentiment
It could be the case that the titles for backs have a different sentiment from the titles for fronts. To analyze the sentiment, sentimentAPI was used.
Using a LinearSVC classifier model, the sentimentAPI was trained on movie reviews and claims to be 88% accurate. For this analysis, a more appropriate model to use would have been one trained on human labeled data of article titles but no such data set was found.

Title Sentitment
Looking at the chart, the sentiment for both backs and fronts is nearly identical. Curiously, the sentiment is slightly negative for both but this could be entirely due to noise.
Using R, a t-test was run comparing the difference between the mean sentiment for backs and fronts.
Welch Two Sample t-test
data: data.fronts and data.backs
t = 0.71427, df = 882.12, p-value = 0.4752
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.01694742 0.03634044
sample estimates:
mean of x mean of y
-0.08209647 -0.09179298Vector Projection
Using the bag-of-words model, we vectorize the back and front titles into their own title by word matrices. Taking these two highly dimensional matrices (M HN submission titles by N words), we reduce their dimensionality in order to visualize them. The three dimensionality reduction methods used were Locally Linear Embedding (LLE), Multidimensional Scaling (MDS), and t-distributed Stochastic Neighbor Embedding (t-SNE).

Locally Linear Embedding
Using LLE, we see a nice separation between backs (the blue circles) and fronts (the red pentagons). There is some overlap in the large grouping towards the center of the plot.
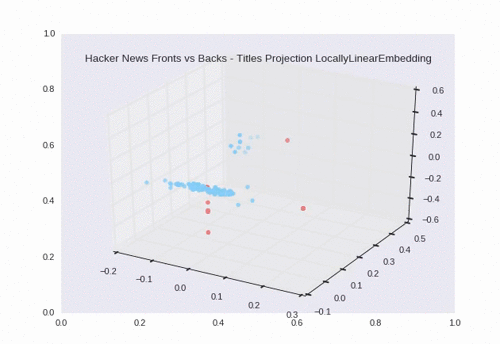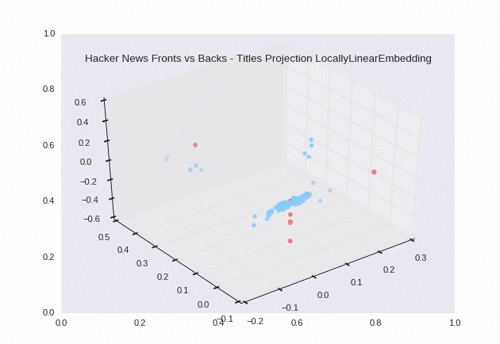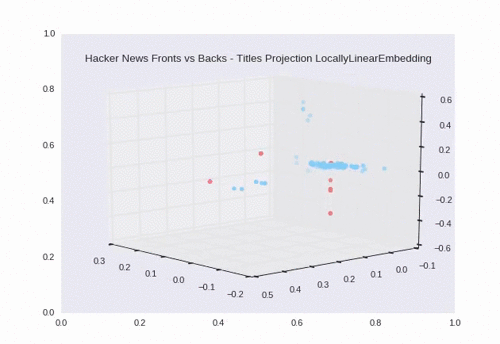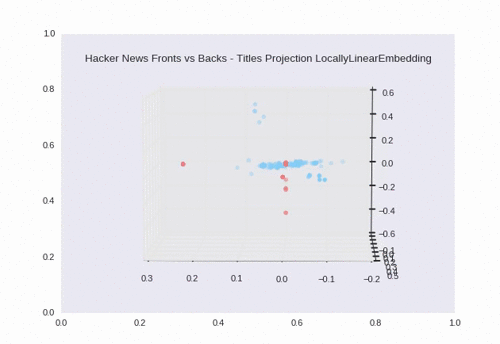
Here we see the dimensions reduced down to 3D.

MDS
In this projection, there is no separation between fronts and backs.

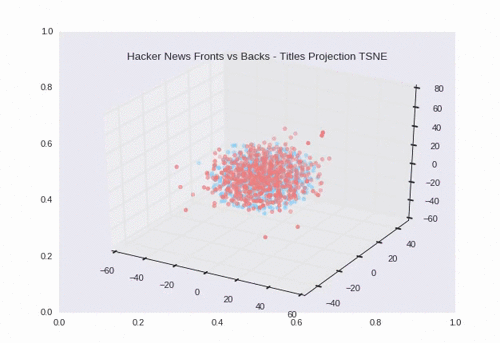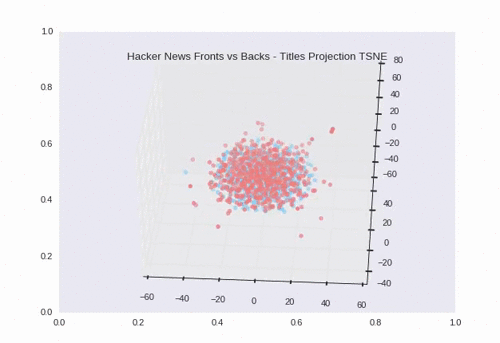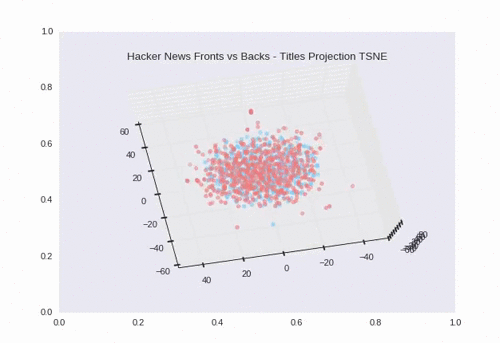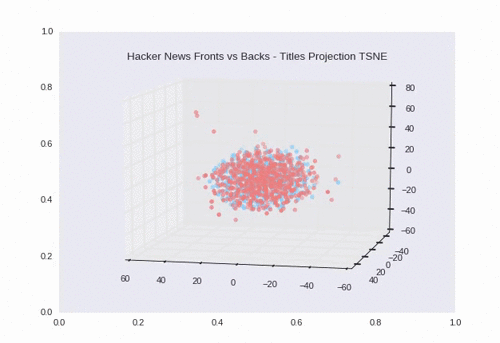
t-SNE
t-SNE is non-deterministic (hence the stochastic). Every run may produce slightly different plots. We can see some separation and overlap which makes sense given the 200 backs that had the same exact title as their front.
User
The users which made the submissions will be the last attribute we look at. Maybe some stories are favored over others merely because of who submitted it from the HN community?

User Relative Frequency
Here is the top of the chart. The full version can be found here (521 KB).
{kind=link}
Based on the sample taken, dnetesn ties with adamnemecek but dnetesn has had more backs than fronts. adamnemecek’s relative frequency of fronts surpasses that of their own relative frequency of backs.
Recap
Using Haskell, R, Python, SQLite, and Elasticsearch, we evaluated posted and reposted pieces of content where only one of the reposts made it to the front page of Hacker News. We looked at the day of the week, time of day, title, and the users which made the submissions. We found statistical significance regarding the dependence between page status and the day of the week. The attributes looked at turned up very little if any patterns distinguishing backs from their related fronts.
Appendix
Below you will find some supplementary material.
Full Source Code
The source code is written in Haskell and embeds the R and Python scripts used. Beyond the languages and their libraries used, you will need SQLite and Elasticsearch to run the following source code.
stack.yaml
resolver: lts-6.11
packages:
- '.'
extra-deps: []
flags: {}
extra-package-dbs: []hackerNewsFrontVsBack.cabal
name: hackerNewsFrontVsBack
version: 0.0.0.1
synopsis: Hacker News front page vs back page story analysis.
description: .
homepage: https://lettier.github.com
license: Apache
license-file: LICENSE
author: David Lettier
copyright: 2016 David Lettier
category: Analysis
build-type: Simple
cabal-version: >=1.10
executable hackerNewsFrontVsBack
hs-source-dirs: src
main-is: Main.hs
default-language: Haskell2010
other-modules: DB
, AlgoliaHits
, HackerNewsItems
, FrontPageItems
, FrontsAndBacks
, Elasticsearch
, DateTimeUtil
, URIUtil
, TimeAnalysis
, TitleAnalysis
, UserAnalysis
, StopWords
, SentimentApi
, Common
build-depends: base >= 4.7 && < 5
, wreq
, aeson
, lens
, bytestring
, sqlite-simple
, network-uri
, text
, hxt
, HandsomeSoup
, time
, containers
, unordered-containers
, data-default-class
, colour
, Chart
, cairo
, Chart-diagrams
, Chart-cairo
, process
, edit-distance
, neat-interpolation
, MissingHMain.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
module Main (main) where
import Control.Monad
import qualified FrontPageItems as FPI
import qualified HackerNewsItems as HNI
import qualified AlgoliaHits as AH
main :: IO ()
main = do
FPI.createDbTableIfNotExists
HNI.createDbTableIfNotExists
AH.createDbTableIfNotExists
FPI.getAllInDb >>= mapM_ (
(return . FPI._id) >=> HNI.idIfNotInDb >=> HNI.getItemMaybe >=> HNI.insertOrReplaceMaybe
)
HNI.getAllInDb >>= mapM_ (AH.getAlgoliaHits >=> mapM_ AH.insertOrReplace)DB.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE QuasiQuotes, OverloadedStrings #-}
module DB where
import GHC.Generics
import Data.Text as DT
import Database.SQLite.Simple
import Database.SQLite.Simple.FromRow
import NeatInterpolation as NI
dbLocation :: String
dbLocation = "data/db/hackerNewsProject.db"
withConnection' :: (Connection -> IO a) -> IO a
withConnection' = withConnection dbLocation
openDb :: IO Connection
openDb = open dbLocation
createDbTableIfNotExists :: String -> String -> IO ()
createDbTableIfNotExists tableName attributes = withConnection' (run (sqlString tableName attributes))
where
sqlString tableName attributes = [NI.text|
CREATE TABLE IF NOT EXISTS ${tableName'} (${attributes'});
|]
where
[tableName', attributes'] = Prelude.map DT.pack [tableName, attributes]
run statement con = execute_ con (Query statement)Common.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE OverloadedStrings #-}
module Common where
import System.Process
import Control.Monad
import Data.Maybe
import Data.List as DL
import Data.Map as DM
import Data.Set as DS
import Data.Text as DT
import qualified Data.ByteString.Lazy as DBL
import Data.Aeson
import NeatInterpolation as NI
runRFile :: String -> IO ()
runRFile rfile = void $ createProcess (proc "R" ["--quiet", "-f", rfile])
esAggBackFrontFieldResult :: (a -> [(String, Integer)]) -> IO [a] -> IO ([(String, Integer)], [(String, Integer)])
esAggBackFrontFieldResult f r = do
r' <- r
let backs = f $ Prelude.head r'
let fronts = f $ Prelude.last r'
return (backs, fronts)
makeKeyMap :: Integer -> [(String, Integer)] -> Map String Double
makeKeyMap t l = DM.fromListWith (+) (Prelude.map (\ (k, x) -> (k, fromInteger x / fromInteger t)) l)
makeAllKeyMap :: [String] -> DM.Map String Double -> DM.Map String Double
makeAllKeyMap keys m = Prelude.foldl (\ acc (k, v) -> DM.insertWith (+) k v acc) m [(k, 0.0) | k <- keys]
lookupKey :: String -> DM.Map String Double -> Double
lookupKey key m = fromMaybe 0.0 (DM.lookup key m)
secondSum :: Num b => [(a, b)] -> b
secondSum = Prelude.sum . Prelude.map snd
writeROrPyFile :: (Text -> Text -> Text) -> String -> String -> String -> IO ()
writeROrPyFile f a b rpyf = writeFile rpyf $ DT.unpack $ f (DT.pack a) (DT.pack b)
notNull :: [a] -> Bool
notNull = Prelude.not . Prelude.null
fst' :: (a, b, c, d) -> a
fst' (a, b, c, d) = aDateTimeUtil.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
module DateTimeUtil where
import Data.Time.Clock
import Data.Time.Clock.POSIX
import Data.Time.LocalTime
import Data.Time.Format
edt :: TimeZone
edt = hoursToTimeZone (-4)
utcTime :: Integer -> UTCTime
utcTime = posixSecondsToUTCTime . fromIntegral
edtZonedTime :: Integer -> ZonedTime
edtZonedTime i = utcToZonedTime edt $ utcTime i
monthOfYearEdtZonedTime :: Integer -> Integer
monthOfYearEdtZonedTime i = read (fEdtZonedTime "%m" i) :: Integer
dayOfWeekEdtZonedTime :: Integer -> Integer
dayOfWeekEdtZonedTime i = read (fEdtZonedTime "%u" i) :: Integer
hourOfDayEdtZonedTime :: Integer -> Integer
hourOfDayEdtZonedTime i = read (fEdtZonedTime "%H" i) :: Integer
minOfHourEdtZonedTime :: Integer -> Integer
minOfHourEdtZonedTime i = read (fEdtZonedTime "%M" i) :: Integer
fEdtZonedTime :: String -> Integer -> String
fEdtZonedTime s i = formatTime defaultTimeLocale s $ edtZonedTime iURIUtil.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE OverloadedStrings #-}
module URIUtil where
import Control.Monad
import Network.URI hiding (query)
import Data.List as DL
import Data.Maybe
import Data.String.Utils as DSU
import Data.Text as DT
import Data.ByteString.Lazy
import qualified Common as CO
uriNoQuery :: String -> String
uriNoQuery s = uriParsed
where
s' = cleanUri s
uri' = uri s'
uriAuth' = uriAuth uri'
isYoutube = "youtube" `DL.isInfixOf` s'
uriParsed = if isURI s' && not isYoutube then Prelude.concat [
uriScheme uri'
, "//"
, uriRegName uriAuth'
, uriPath uri'
] else s'
uri :: String -> URI
uri string = fromMaybe nullURI (parseURI $ DT.unpack $ DT.toLower $ DT.pack string)
uriAuth :: URI -> URIAuth
uriAuth uri = fromMaybe (URIAuth "" "" "") (uriAuthority uri)
uriHost :: URI -> String
uriHost = uriRegName . uriAuth
uriTLD :: URI -> String
uriTLD u = grabTLD chunks
where
chunks = uriHostChunks u
grabTLD :: [String] -> String
grabTLD [] = ""
grabTLD [a, b, "co", _] = "com"
grabTLD [a, "co", _] = "com"
grabTLD [t] = t
grabTLD [d, t] = t
grabTLD [s, d, t] = t
grabTLD [ss, s, d, t] = t
grabTLD (x:y) = Prelude.last (x:y)
uriDomain :: URI -> String
uriDomain u = grabDomain chunks
where
chunks = uriHostChunks u
grabDomain :: [String] -> String
grabDomain [] = ""
grabDomain [a, b, "co", _] = b
grabDomain [a, "co", _] = a
grabDomain [t] = ""
grabDomain [d, t] = d
grabDomain [s, d, t] = d
grabDomain [ss, s, d, t] = d
grabDomain (x:y) = Prelude.last $ Prelude.init (x:y)
uriSubdomain :: URI -> String
uriSubdomain u = grabSubdomain chunks
where
chunks = uriHostChunks u
grabSubdomain :: [String] -> String
grabSubdomain [] = ""
grabSubdomain ["www", a, "co", _] = ""
grabSubdomain [a, b, "co", _] = a
grabSubdomain [a, "co", _] = ""
grabSubdomain ("www":_) = ""
grabSubdomain [t] = ""
grabSubdomain [d, t] = ""
grabSubdomain [s, d, t] = s
grabSubdomain [ss, s, d, t] = ss ++ "." ++ s
grabSubdomain (x:y) = x
parseURIHost :: URI -> [String]
parseURIHost u = [uriSubdomain u, uriDomain u, uriTLD u]
uriHostChunks :: URI -> [String]
uriHostChunks = Prelude.map DT.unpack . DT.split (== '.') . DT.toLower . DT.pack . uriHost
cleanUri :: String -> String
cleanUri s = scheme ++ "//" ++ DL.intercalate "." (
Prelude.filter CO.notNull [subdomain, domain, tld]
) ++ path ++ query
where
uri' = (uri . DT.unpack . DT.toLower . DT.strip . DT.pack) s
scheme = cleanUriScheme $ uriScheme uri'
subdomain = uriSubdomain uri'
domain = uriDomain uri'
tld = uriTLD uri'
path = cleanUriPath $ uriPath uri'
query = cleanUriQuery $ uriQuery uri'
cleanUriScheme :: String -> String
cleanUriScheme "https:" = "https:"
cleanUriScheme "http:" = "https:"
cleanUriScheme x = x
cleanUriPath :: String -> String
cleanUriPath "" = ""
cleanUriPath x = (removeLastIndexExt . removeLastSlash . removeDoubleSlash) x
where
removeDoubleSlash :: String -> String
removeDoubleSlash = DSU.replace "//" "/"
removeLastIndexExt :: String -> String
removeLastIndexExt = recombine . parts
where
parts :: String -> [String]
parts = DSU.split "/"
lastPart :: [String] -> String
lastPart [] = ""
lastPart y = Prelude.last y
recombine [] = ""
recombine z = DL.intercalate "/" (if "index." `DL.isInfixOf` lastPart z then Prelude.init z else z)
removeLastSlash :: String -> String
removeLastSlash "" = ""
removeLastSlash a = if Prelude.last a == '/' then Prelude.init a else a
cleanUriQuery :: String -> String
cleanUriQuery "" = ""
cleanUriQuery "?" = ""
cleanUriQuery "?=" = ""
cleanUriQuery "?=&" = ""
cleanUriQuery q = if DL.isInfixOf "?" q && DL.isInfixOf "=" q && Prelude.length q > 3 then q else ""StopWords.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE OverloadedStrings #-}
module StopWords where
-- Taken from http://xpo6.com/list-of-english-stop-words/
stopWords :: [String]
stopWords = [
-- ...
]FrontPageItems.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE DeriveGeneric, QuasiQuotes, OverloadedStrings #-}
module FrontPageItems where
import GHC.Generics
import Control.Lens
import Control.Monad
import Control.Exception
import Control.Applicative
import Control.Concurrent
import Network.URI hiding (query)
import Data.Maybe
import Data.Either
import Data.Time
import Data.Time.Clock.POSIX
import Data.Text as DT
import Data.ByteString.Lazy
import Data.ByteString.Lazy.Char8
import Data.Aeson
import Data.Aeson.Types
import Network.Wreq
import Database.SQLite.Simple
import Database.SQLite.Simple.FromRow
import Text.XML.HXT.Core
import Text.HandsomeSoup
import NeatInterpolation as NI
import DB
data FrontPageItem = FrontPageItem {
_id :: Integer
, user :: String
, points :: Integer
, url :: String
, title :: String
, timestamp :: Integer
} deriving (Show, Generic)
instance FromRow FrontPageItem where
fromRow = FrontPageItem <$> field
<*> field
<*> field
<*> field
<*> field
<*> field
instance ToRow FrontPageItem where
toRow (FrontPageItem _id user points title url timestamp) = toRow (
_id
, user
, points
, title
, url
, timestamp
)
dbTableName :: String
dbTableName = "frontPageItems"
startDay :: Day
startDay = fromGregorian 2016 09 05
-- 2016 06 24
daysBack :: [Integer]
daysBack = [0..73]
frontPageItemsApi :: String
frontPageItemsApi = "https://news.ycombinator.com/front"
byteStringToString :: ByteString -> IO String
byteStringToString = return . Data.ByteString.Lazy.Char8.unpack
dayToInteger :: Day -> Integer
dayToInteger d = read (Prelude.init $ show $ utcTimeToPOSIXSeconds $ UTCTime d 0) :: Integer
getRawHtml :: Day -> Integer -> IO (Response ByteString)
getRawHtml day page = getWith opts frontPageItemsApi
where
opts = defaults & param "day" .~ [(DT.pack . showGregorian) day] & param "p" .~ [DT.pack $ show page]
processResponse :: Response ByteString -> IO ByteString
processResponse rbs = return (rbs ^. responseBody)
getFrontPageDays :: IO ()
getFrontPageDays = mapM_ processDay daysBack
where
processDay :: Integer -> IO ()
processDay i = frontPageItems >>= mapM_ insertOrReplace
where
day = addDays ((-1) * i) startDay
frontPageItems :: IO [FrontPageItem]
frontPageItems = foldM (\ acc page -> do
Control.Monad.when (page > 1) $ threadDelay (30 * 1000000)
print day
result <- getFrontPageDay day page
return (acc ++ result)
) [] [1..5]
getFrontPageDay :: Day -> Integer -> IO [FrontPageItem]
getFrontPageDay day page = getRawHtml day page >>= processResponse >>= byteStringToString >>= processHtml
where
processHtml :: String -> IO [FrontPageItem]
processHtml htmlString = makeFrontPageItems
where
doc :: IOStateArrow s b XmlTree
doc = readString [withParseHTML yes, withWarnings yes] htmlString
tr = doc >>> css "tr"
idUrlTitle = hasAttrValue "class" (== "athing") >>> hasAttr "id" >>> (
getAttrValue "id" &&& (
css "a" >>> hasAttrValue "class" (== "storylink") >>> (
getAttrValue "href" &&& (getChildren >>> getText)
)
)
)
userPoints = css "td" >>> hasAttrValue "class" (== "subtext") >>> multi ((
css "a" >>> hasAttrValue "class" (== "hnuser") >>> getChildren >>> getText
) &&& (
css "span" >>> hasAttrValue "class" (== "score") >>> getChildren >>> getText
))
idUrlTitleParsed = runX $ tr >>> idUrlTitle
userPointsParsed = runX $ tr >>> userPoints
mergedParsed = do
x <- idUrlTitleParsed
y <- userPointsParsed
return (Prelude.zip x y)
makeFrontPageItem :: ((String, (String, String)), (String, String)) -> FrontPageItem
makeFrontPageItem ((i, (ur, t)), (u, p)) = FrontPageItem {
_id = read i :: Integer
, user = u
, points = read (Prelude.head $ Prelude.words p) :: Integer
, url = ur
, title = t
, timestamp = dayToInteger day
}
makeFrontPageItems = fmap (Prelude.map makeFrontPageItem) mergedParsed
createDbTableIfNotExists :: IO ()
createDbTableIfNotExists = DB.createDbTableIfNotExists dbTableName attributes
where
attributes = DT.unpack [NI.text|
_id INTEGER PRIMARY KEY
, user TEXT
, points INTEGER
, url INTEGER
, title TEXT
, timestamp INTEGER
|]
insertOrReplace :: FrontPageItem -> IO ()
insertOrReplace FrontPageItem {
_id = i
, user = u
, points = p
, title = t
, url = url'
, timestamp = ts
} = void insertOrReplaceTryResult
where
tryInsertOrReplace = try (withConnection' insertOrReplace) :: IO (Either SomeException ())
insertOrReplaceTryResult = tryInsertOrReplace >>= either (void . print) return
insertOrReplace :: Connection -> IO ()
insertOrReplace con = execute con "REPLACE INTO ? (\
\ _id \
\ , user \
\ , points \
\ , url \
\ , title \
\ , timestamp \
\ ) values (?, ?, ?, ?, ?, ?);" (
dbTableName
, i
, u
, p
, t
, url'
, ts
)
getAllInDb :: IO [FrontPageItem]
getAllInDb = withConnection' queryForItems
where
queryForItems :: Connection -> IO [FrontPageItem]
queryForItems con = query con "SELECT * FROM ?;" (Only dbTableName)HackerNewsItems.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE DeriveGeneric, QuasiQuotes, OverloadedStrings #-}
module HackerNewsItems where
import GHC.Generics
import Control.Lens
import Control.Monad
import Control.Exception
import Control.Applicative
import Network.URI hiding (query)
import Data.Maybe
import Data.Either
import Data.Text as DT
import Data.ByteString.Lazy
import Data.Aeson
import Data.Aeson.Types
import Network.Wreq
import Database.SQLite.Simple
import Database.SQLite.Simple.FromRow
import NeatInterpolation as NI
import DB
import qualified FrontPageItems as FPI
data HackerNewsItem = HackerNewsItem {
_id :: Integer
, by :: String
, score :: Integer
, time :: Integer
, title :: String
, typee :: String
, url :: String
} deriving (Show, Generic)
instance FromJSON HackerNewsItem where
parseJSON (Object v) =
HackerNewsItem <$> v .: "id"
<*> v .: "by"
<*> v .: "score"
<*> v .: "time"
<*> v .: "title"
<*> v .: "type"
<*> v .: "url"
instance FromRow HackerNewsItem where
fromRow = HackerNewsItem <$> field
<*> field
<*> field
<*> field
<*> field
<*> field
<*> field
instance ToRow HackerNewsItem where
toRow (HackerNewsItem _id by score time title typee url) = toRow (
_id
, by
, score
, time
, title
, typee
, url
)
dbTableName :: String
dbTableName = "hackerNewsItems"
topStoriesApi :: String
topStoriesApi = "https://hacker-news.firebaseio.com/v0/topstories.json"
itemsApi :: Integer -> String
itemsApi itemId = Prelude.concat ["https://hacker-news.firebaseio.com/v0/item/", show itemId, ".json"]
getTopStoryItemIds :: IO (Maybe [Integer])
getTopStoryItemIds = do
r <- get topStoriesApi
return (decode (r ^. responseBody) :: Maybe [Integer])
getItems :: Maybe [Integer] -> IO [Maybe HackerNewsItem]
getItems = maybe (return []) (mapM getItem)
getItem :: Integer -> IO (Maybe HackerNewsItem)
getItem itemId = do
print itemId
r <- try(get $ itemsApi itemId) :: IO (Either SomeException (Response ByteString))
case r of
Left e -> print e >> return Nothing
Right bs -> return (decode (bs ^. responseBody) :: Maybe HackerNewsItem)
getItemMaybe :: Maybe Integer -> IO (Maybe HackerNewsItem)
getItemMaybe = maybe (return Nothing) getItem
createDbTableIfNotExists :: IO ()
createDbTableIfNotExists = DB.createDbTableIfNotExists dbTableName attributes
where
attributes = DT.unpack [NI.text|
_id INTEGER PRIMARY KEY\
, by TEXT
, score INTEGER
, time INTEGER
, title TEXT
, typee TEXT
, url TEXT
|]
getItemInDb :: Integer -> IO (Maybe HackerNewsItem)
getItemInDb itemId = withConnection' queryForItem >>= firstItem
where
queryForItem :: Connection -> IO [HackerNewsItem]
queryForItem con = query con "SELECT * FROM ? where _id = ? LIMIT 1;" (dbTableName, itemId) :: IO [HackerNewsItem]
firstItem :: [HackerNewsItem] -> IO (Maybe HackerNewsItem)
firstItem (x:y) = return (Just x)
firstItem [] = return Nothing
getUrlsInDb :: IO [String]
getUrlsInDb = withConnection' queryForUrls >>= urls
where
queryForUrls :: Connection -> IO [[String]]
queryForUrls con = query con "SELECT url FROM ?;" (Only dbTableName) :: IO [[String]]
urls :: [[String]] -> IO [String]
urls [] = return []
urls (x:y) = return (Prelude.map extractUrl (x:y))
extractUrl :: [String] -> String
extractUrl [] = ""
extractUrl (x:y) = x
getAllInDb :: IO [HackerNewsItem]
getAllInDb = withConnection' queryForItems
where
queryForItems :: Connection -> IO [HackerNewsItem]
queryForItems con = query con "SELECT * FROM ?;" (Only dbTableName)
getStoriesInDb :: IO [HackerNewsItem]
getStoriesInDb = withConnection' queryForItems
where
queryForItems :: Connection -> IO [HackerNewsItem]
queryForItems con = query con "SELECT * FROM ? where typee = 'story' and _id in (select _id from ?);" (
dbTableName
, FPI.dbTableName
)
existsInDb :: Integer -> IO Bool
existsInDb itemId = getItemInDb itemId >>= maybe (return False) (\ _ -> return True)
idIfNotInDb :: Integer -> IO (Maybe Integer)
idIfNotInDb itemId = existsInDb itemId >>= \ exists -> if exists then return Nothing else return (Just itemId)
insertOrReplaceMaybe :: Maybe HackerNewsItem -> IO ()
insertOrReplaceMaybe = maybe (return ()) insertOrReplace
insertOrReplace :: HackerNewsItem -> IO ()
insertOrReplace HackerNewsItem {
_id = i
, by = b
, score = s
, time = t
, title = title'
, typee = typee'
, url = u
} = withConnection' insertOrReplace
where
insertOrReplace :: Connection -> IO ()
insertOrReplace con = execute con "REPLACE INTO ? (\
\_id\
\, by\
\, score\
\, time\
\, title\
\, typee\
\, url\
\) values (?, ?, ?, ?, ?, ?, ?);" (
dbTableName
, i
, b
, s
, t
, title'
, typee'
, u
)AlgoliaHits.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE DeriveGeneric, QuasiQuotes, OverloadedStrings #-}
module AlgoliaHits where
import GHC.Generics
import Control.Lens
import Control.Monad
import Control.Exception
import Control.Applicative
import Network.URI hiding (query)
import Data.Maybe
import Data.List as DL
import Data.Text as DT
import Data.ByteString.Lazy
import Data.Aeson
import Data.Aeson.Types
import Text.EditDistance
import Network.Wreq
import Database.SQLite.Simple
import Database.SQLite.Simple.FromRow
import NeatInterpolation as NI
import DB
import URIUtil
import qualified Common as CO
import qualified HackerNewsItems as HNI
data AlgoliaHit = AlgoliaHit {
_id :: Integer
, author :: String
, points :: Integer
, createdAt :: Integer
, title :: String
, url :: Maybe String
, hackerNewsItemsId :: Integer
} deriving (Show, Generic)
data AlgoliaHits = AlgoliaHits {
hits :: [AlgoliaHit]
} deriving (Show, Generic)
instance FromJSON AlgoliaHit where
parseJSON = withObject "hit" $ \ o -> do
_id' <- o .: "objectID"
author <- o .: "author"
points <- o .: "points"
createdAt <- o .: "created_at_i"
title <- o .: "title"
url <- o .: "url"
let _id'' = read _id' :: Integer
return (AlgoliaHit _id'' author points createdAt title url 0)
instance FromJSON AlgoliaHits where
parseJSON (Object v) =
AlgoliaHits <$> v .: "hits"
instance FromRow AlgoliaHit where
fromRow = AlgoliaHit <$> field
<*> field
<*> field
<*> field
<*> field
<*> field
<*> field
instance ToRow AlgoliaHit where
toRow (AlgoliaHit _id author points createdAt title url hackerNewsItemsId) = toRow (
_id
, author
, points
, createdAt
, title
, url
, hackerNewsItemsId
)
dbTableName :: String
dbTableName = "algoliaHits"
algoliaSearchApi :: String
algoliaSearchApi = "http://hn.algolia.com/api/v1/search"
getAlgoliaHits :: HNI.HackerNewsItem -> IO [AlgoliaHit]
getAlgoliaHits hni = do
exists' <- urlExistsInDb url'
if exists'
then print ("Skipping " ++ url') >> return []
else do
print url'
r <- try(getWith opts algoliaSearchApi) :: IO (Either SomeException (Response ByteString))
case r of
Left e -> print e >> return []
Right bs -> do
let json = bs ^. responseBody
let eitherAlgoliaHits = eitherDecode json :: Either String AlgoliaHits
case eitherAlgoliaHits of
Left s -> print s >> return []
Right ah -> return $ Prelude.map (\ h -> h { hackerNewsItemsId = foreignId }) (hits ah)
where
url' = HNI.url hni
foreignId = HNI._id hni
opts = defaults & param "query" .~ [DT.pack $ uriNoQuery url'] & param "tags" .~ ["story"]
createDbTableIfNotExists :: IO ()
createDbTableIfNotExists = DB.createDbTableIfNotExists dbTableName attributes
where
attributes = DT.unpack [NI.text|
_id INTEGER PRIMARY KEY
, author TEXT
, points INTEGER
, createdAt INTEGER
, title TEXT
, url TEXT
, hackerNewsItemsId INTEGER
, FOREIGN KEY('${hniDbTableName}Id') REFERENCES ${hniDbTableName}(_id)
|]
where
hniDbTableName = DT.pack HNI.dbTableName
getHitInDb :: Integer -> IO (Maybe AlgoliaHit)
getHitInDb hitId = withConnection' queryForHit >>= firstHit
where
queryForHit :: Connection -> IO [AlgoliaHit]
queryForHit con = query con "SELECT * FROM ? WHERE _id = ? LIMIT 1;" (dbTableName, hitId) :: IO [AlgoliaHit]
firstHit :: [AlgoliaHit] -> IO (Maybe AlgoliaHit)
firstHit (x:y) = return (Just x)
firstHit [] = return Nothing
getHitsWithUrlInDb :: String -> IO [AlgoliaHit]
getHitsWithUrlInDb url' = withConnection' queryForHits
where
queryForHits :: Connection -> IO [AlgoliaHit]
queryForHits con = query con "SELECT * FROM ? WHERE url LIKE ?;" (dbTableName, url' ++ "%") :: IO [AlgoliaHit]
getUrlMatchesInDb :: IO [(Integer, Integer, Maybe String, Maybe String)]
getUrlMatchesInDb = do
result <- withConnection' queryDB
let matches = Prelude.filter ((/= -1) . CO.fst') (
Prelude.map (\ (ahId, hniId, ahUrl, hniUrl) ->
if match ahUrl hniUrl then (ahId, hniId, ahUrl, hniUrl) else (-1, -1, Just "", Just "")
) result
)
return matches
where
queryDB :: Connection -> IO [(Integer, Integer, Maybe String, Maybe String)]
queryDB con = query_ con (Query $ sqlString (DT.pack dbTableName) (DT.pack HNI.dbTableName))
sqlString dbTableName hniDbTableName = [NI.text|
SELECT ah._id, hni._id, ah.url, hni.url FROM
${dbTableName} AS ah INNER JOIN ${hniDbTableName}
AS hni ON ah.${hniDbTableName}Id = hni._id
|]
match :: Maybe String -> Maybe String -> Bool
match Nothing Nothing = True
match Nothing _ = False
match _ Nothing = False
match (Just ahUrl) (Just hniUrl) = tldDist == 0 && domainDist == 0 && subDomainDist < 10 && pathDist < 2 && queryDist == 0
where
ahUri = uri $ cleanUri ahUrl
hniUri = uri $ cleanUri hniUrl
[ahTLD, hniTLD] = Prelude.map uriTLD [ahUri, hniUri]
[ahDomain, hniDomain] = Prelude.map uriDomain [ahUri, hniUri]
[ahSubdomain, hniSubdomain] = Prelude.map uriSubdomain [ahUri, hniUri]
[ahPath, hniPath] = Prelude.map uriPath [ahUri, hniUri]
[ahQuery, hniQuery] = Prelude.map uriQuery [ahUri, hniUri]
ahQuery' = if CO.notNull ahPath then "" else ahQuery
hniQuery' = if CO.notNull hniPath then "" else hniQuery
[tldDist, domainDist, subDomainDist, pathDist, queryDist] = Prelude.map (
uncurry (levenshteinDistance defaultEditCosts)) [
(ahTLD, hniTLD)
, (ahDomain, hniDomain)
, (ahSubdomain, hniSubdomain)
, (ahPath, hniPath)
, (ahQuery', hniQuery')
]
algoliaHitsIdsFromUrlMatches :: IO [Integer]
algoliaHitsIdsFromUrlMatches = getUrlMatchesInDb >>= mapM (return . CO.fst')
fixHitsForeignIds :: HNI.HackerNewsItem -> IO ()
fixHitsForeignIds hni = hits' >>= mapM_ insertOrReplace
where
foreignId = HNI._id hni
updateForeignId h = do
let h' = h { hackerNewsItemsId = foreignId }
print h'
return h'
hits' = getHitsWithUrlInDb (HNI.url hni) >>= mapM updateForeignId
existsInDb :: Integer -> IO Bool
existsInDb hitId = getHitInDb hitId >>= maybe (return False) (\ _ -> return True)
urlExistsInDb :: String -> IO Bool
urlExistsInDb url = (
try (withConnection' queryForUrl >>= exists) :: IO (Either SomeException Bool)
) >>= either (\ e -> print e >> return False) return
where
queryForUrl :: Connection -> IO [[String]]
queryForUrl con = query con "SELECT url FROM ? WHERE url LIKE ? LIMIT 1;" (dbTableName, url ++ "%") :: IO [[String]]
exists :: [[String]] -> IO Bool
exists [] = return False
exists (x:y) = if Prelude.null x then return False else return True
idIfNotInDb :: Integer -> IO (Maybe Integer)
idIfNotInDb hitId = existsInDb hitId >>= \ exists -> if exists then return Nothing else return (Just hitId)
insertOrReplaceMaybe :: Maybe AlgoliaHit -> IO ()
insertOrReplaceMaybe = maybe (return ()) insertOrReplace
insertOrReplace :: AlgoliaHit -> IO ()
insertOrReplace AlgoliaHit {
_id = i
, author = a
, points = p
, createdAt = c
, title = t
, url = u
, hackerNewsItemsId = hniId
} = void (try (withConnection' insertOrReplace) :: IO (Either SomeException ()))
where
insertOrReplace :: Connection -> IO ()
insertOrReplace con = execute con "REPLACE INTO ? (\
\ _id \
\ , author \
\ , points \
\ , createdAt \
\ , title \
\ , url \
\ , hackerNewsItemsId \
\ ) values (?, ?, ?, ?, ?, ?, ?);" (
dbTableName
, i
, a
, p
, t
, u
, hniId
)Elasticsearch.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE OverloadedStrings #-}
module Elasticsearch where
import GHC.Generics
import Control.Lens hiding ((.=))
import Control.Monad
import Network.URI hiding (query)
import Data.Maybe
import Data.Text as DT
import Data.ByteString.Lazy
import Data.Aeson
import Data.Aeson.Types
import Data.Map
import Network.Wreq as W
import DB
import DateTimeUtil as DTU
import qualified FrontPageItems as FPI
import qualified HackerNewsItems as HNI
import qualified AlgoliaHits as AH
import qualified FrontsAndBacks as FAB
import qualified StopWords as SW
instance ToJSON HNI.HackerNewsItem where
toJSON hni = object [
"id" .= HNI._id hni
, "user" .= HNI.by hni
, "points" .= HNI.score hni
, "url" .= HNI.url hni
, "title" .= HNI.title hni
, "date" .= (1000 * HNI.time hni)
, "month" .= DTU.monthOfYearEdtZonedTime (HNI.time hni)
, "day" .= DTU.dayOfWeekEdtZonedTime (HNI.time hni)
, "hour" .= DTU.hourOfDayEdtZonedTime (HNI.time hni)
, "mininute" .= DTU.minOfHourEdtZonedTime (HNI.time hni)
]
instance ToJSON AH.AlgoliaHit where
toJSON ah = object [
"id" .= AH._id ah
, "user" .= AH.author ah
, "points" .= AH.points ah
, "url" .= AH.url ah
, "title" .= AH.title ah
, "date" .= (1000 * AH.createdAt ah)
, "month" .= DTU.monthOfYearEdtZonedTime (AH.createdAt ah)
, "day" .= DTU.dayOfWeekEdtZonedTime (AH.createdAt ah)
, "hour" .= DTU.hourOfDayEdtZonedTime (AH.createdAt ah)
, "minute" .= DTU.minOfHourEdtZonedTime (AH.createdAt ah)
, "frontId" .= AH.hackerNewsItemsId ah
]
elasticsearchLocation :: String
elasticsearchLocation = "http://localhost:9200/"
elasticsearchIndexName :: String
elasticsearchIndexName = "hackernewsfrontback/"
elasticsearchIndex = elasticsearchLocation ++ elasticsearchIndexName
deleteIndex :: IO ()
deleteIndex = void $ W.delete elasticsearchIndex
createIndex :: IO ()
createIndex = void(post elasticsearchIndex json)
where
json = object [
"mappings" .= object [
"front" .= object [
"properties" .= object [
"id" .= object [
"type" .= ("integer" :: String)
, "index" .= ("not_analyzed" :: String)
]
,
"user" .= object [
"type" .= ("string" :: String)
, "index" .= ("not_analyzed" :: String)
]
,
"points" .= object [
"type" .= ("integer" :: String)
]
,
"url" .= object [
"type" .= ("string" :: String)
, "index" .= ("not_analyzed" :: String)
]
,
"title" .= object [
"type" .= ("string" :: String)
, "analyzer" .= ("english" :: String)
]
,
"date" .= object [
"type" .= ("date" :: String)
]
,
"month" .= object [
"type" .= ("integer" :: String)
]
,
"day" .= object [
"type" .= ("integer" :: String)
]
,
"hour" .= object [
"type" .= ("integer" :: String)
]
,
"minute" .= object [
"type" .= ("integer" :: String)
]
]
]
,
"back" .= object [
"_parent" .= object [
"type" .= ("front" :: String)
]
,
"properties" .= object [
"id" .= object [
"type" .= ("integer" :: String)
, "index" .= ("not_analyzed" :: String)
]
,
"user" .= object [
"type" .= ("string" :: String)
, "index" .= ("not_analyzed" :: String)
]
,
"points" .= object [
"type" .= ("integer" :: String)
]
,
"url" .= object [
"type" .= ("string" :: String)
, "index" .= ("not_analyzed" :: String)
]
,
"title" .= object [
"type" .= ("string" :: String)
, "analyzer" .= ("english" :: String)
]
,
"date" .= object [
"type" .= ("date" :: String)
]
,
"month" .= object [
"type" .= ("integer" :: String)
]
,
"day" .= object [
"type" .= ("integer" :: String)
]
,
"hour" .= object [
"type" .= ("integer" :: String)
]
,
"minute" .= object [
"type" .= ("integer" :: String)
]
,
"frontId" .= object [
"type" .= ("integer" :: String),
"index" .= ("not_analyzed" :: String)
]
]
]
]
]
indexFronts :: IO ()
indexFronts = FAB.getFrontsInDb >>= mapM_ index
where
index x = put (elasticsearchIndex ++ "front/" ++ _id x) $ toJSON x
_id = show . HNI._id
indexBacks :: IO ()
indexBacks = FAB.getBacksInDb >>= mapM_ index
where
index x = putWith (opts x) (elasticsearchIndex ++ "back/" ++ _id x) $ toJSON x
opts x = defaults & param "parent" .~ [DT.pack $ show $ AH.hackerNewsItemsId x]
_id = show . AH._id
createAndFillIndex :: IO ()
createAndFillIndex = deleteIndex >> createIndex >> indexFronts >> indexBacks
--------------------------------------------------------------------------------
runEsAgg :: Value -> IO Value
runEsAgg v = postWith opts (elasticsearchIndex ++ "_search") v >>= parseResponse
where
opts = defaults & param "search_type" .~ ["count"]
parseResponse :: Response ByteString -> IO Value
parseResponse r = return (fromMaybe (object []) (decode (r ^. responseBody) :: Maybe Value))
parseAgg :: (Value -> Parser [a]) -> Value -> Either String [a]
parseAgg = parseEither
aggResult :: (Value -> Either String [a]) -> IO Value -> IO [a]
aggResult f = fmap (either (const []) id . f)
keyDocCountParser :: FromJSON a => Value -> Parser (a, Integer)
keyDocCountParser = withObject "keyDocCount" (\ obj -> do
k <- obj .: "key"
v <- obj .: "doc_count"
return (k, v)
)
--------------------------------------------------------------------------------
esAggDayHour :: IO Value
esAggDayHour = runEsAgg json
where
json = object [
"aggs" .= object [
"type" .= object [
"terms" .= object [
"field" .= ("_type" :: String)
, "size" .= (2 :: Integer)
, "order" .= object [
"_term" .= ("asc" :: String)
]
]
,
"aggs" .= object [
"day" .= object [
"terms" .= object [
"field" .= ("day" :: String)
, "size" .= (7 :: Integer)
, "order" .= object [
"_term" .= ("asc" :: String)
]
]
]
,
"hour" .= object [
"terms" .= object [
"field" .= ("hour" :: String)
, "size" .= (24 :: Integer)
, "order" .= object [
"_term" .= ("asc" :: String)
]
]
]
]
]
]
]
data AggDayHourResult = AggDayHourResult {
aggDayHourTypeKey :: String
, aggDay :: [(Integer, Integer)]
, aggHour :: [(Integer, Integer)]
} deriving (Show)
aggDayHourParser :: Value -> Parser [AggDayHourResult]
aggDayHourParser = withObject "agg" (\ obj -> do
aggs <- obj .: "aggregations"
typee <- aggs .: "type"
(bucket1:bucket2:y) <- typee .: "buckets"
bucket1Key <- (bucket1 .: "key") :: Parser String
dayBucket1 <- bucket1 .: "day"
dayBucket1Buckets <- dayBucket1 .: "buckets"
dayBucket1Buckets' <- mapM keyDocCountParser dayBucket1Buckets :: Parser [(Integer, Integer)]
hourBucket1 <- bucket1 .: "hour"
hourBucket1Buckets <- hourBucket1 .: "buckets"
hourBucket1Buckets' <- mapM keyDocCountParser hourBucket1Buckets :: Parser [(Integer, Integer)]
bucket2Key <- (bucket2 .: "key") :: Parser String
dayBucket2 <- bucket2 .: "day"
dayBucket2Buckets <- dayBucket2 .: "buckets"
dayBucket2Buckets' <- mapM keyDocCountParser dayBucket2Buckets :: Parser [(Integer, Integer)]
hourBucket2 <- bucket2 .: "hour"
hourBucket2Buckets <- hourBucket2 .: "buckets"
hourBucket2Buckets' <- mapM keyDocCountParser hourBucket2Buckets :: Parser [(Integer, Integer)]
return [
AggDayHourResult { aggDayHourTypeKey = bucket1Key, aggDay = dayBucket1Buckets', aggHour = hourBucket1Buckets' }
, AggDayHourResult { aggDayHourTypeKey = bucket2Key, aggDay = dayBucket2Buckets', aggHour = hourBucket2Buckets' }
]
)
parseAggDayHour :: Value -> Either String [AggDayHourResult]
parseAggDayHour = parseAgg aggDayHourParser
aggDayHourResult :: IO [AggDayHourResult]
aggDayHourResult = aggResult parseAggDayHour esAggDayHour
--------------------------------------------------------------------------------
esAggTitle :: IO Value
esAggTitle = runEsAgg json
where
json = object [
"aggs" .= object [
"type" .= object [
"terms" .= object [
"field" .= ("_type" :: String)
, "size" .= (2 :: Integer)
, "order" .= object [
"_term" .= ("asc" :: String)
]
]
,
"aggs" .= object [
"title" .= object [
"terms" .= object [
"field" .= ("title" :: String)
, "size" .= (10000000 :: Integer)
, "min_doc_count" .= (1 :: Integer)
, "exclude" .= SW.stopWords
, "order" .= object [
"_term" .= ("asc" :: String)
]
]
]
]
]
]
]
data AggTitleResult = AggTitleResult {
aggTitleTypeKey :: String
, aggTitle :: [(String, Integer)]
} deriving (Show)
aggTitleParser :: Value -> Parser [AggTitleResult]
aggTitleParser = withObject "agg" (\ obj -> do
aggs <- obj .: "aggregations"
typee <- aggs .: "type"
(bucket1:bucket2:y) <- typee .: "buckets"
bucket1Key <- (bucket1 .: "key") :: Parser String
titleBucket1 <- bucket1 .: "title"
titleBucket1Buckets <- titleBucket1 .: "buckets"
titleBucket1Buckets' <- mapM keyDocCountParser titleBucket1Buckets :: Parser [(String, Integer)]
bucket2Key <- (bucket2 .: "key") :: Parser String
titleBucket2 <- bucket2 .: "title"
titleBucket2Buckets <- titleBucket2 .: "buckets"
titleBucket2Buckets' <- mapM keyDocCountParser titleBucket2Buckets :: Parser [(String, Integer)]
return [
AggTitleResult { aggTitleTypeKey = bucket1Key, aggTitle = titleBucket1Buckets' }
, AggTitleResult { aggTitleTypeKey = bucket2Key, aggTitle = titleBucket2Buckets' }
]
)
parseAggTitle :: Value -> Either String [AggTitleResult]
parseAggTitle = parseAgg aggTitleParser
aggTitleResult :: IO [AggTitleResult]
aggTitleResult = aggResult parseAggTitle esAggTitle
--------------------------------------------------------------------------------
esAggUser :: IO Value
esAggUser = runEsAgg json
where
json = object [
"aggs" .= object [
"type" .= object [
"terms" .= object [
"field" .= ("_type" :: String)
, "size" .= (2 :: Integer)
, "order" .= object [
"_term" .= ("asc" :: String)
]
]
,
"aggs" .= object [
"user" .= object [
"terms" .= object [
"field" .= ("user" :: String)
, "size" .= (10000000 :: Integer)
, "min_doc_count" .= (1 :: Integer)
, "order" .= object [
"_count" .= ("desc" :: String)
]
]
]
]
]
]
]
data AggUserResult = AggUserResult {
aggUserTypeKey :: String
, aggUser :: [(String, Integer)]
} deriving (Show)
aggUserParser :: Value -> Parser [AggUserResult]
aggUserParser = withObject "agg" (\ obj -> do
aggs <- obj .: "aggregations"
typee <- aggs .: "type"
(bucket1:bucket2:y) <- typee .: "buckets"
bucket1Key <- (bucket1 .: "key") :: Parser String
userBucket1 <- bucket1 .: "user"
userBucket1Buckets <- userBucket1 .: "buckets"
userBucket1Buckets' <- mapM keyDocCountParser userBucket1Buckets :: Parser [(String, Integer)]
bucket2Key <- (bucket2 .: "key") :: Parser String
userBucket2 <- bucket2 .: "user"
userBucket2Buckets <- userBucket2 .: "buckets"
userBucket2Buckets' <- mapM keyDocCountParser userBucket2Buckets :: Parser [(String, Integer)]
return [
AggUserResult { aggUserTypeKey = bucket1Key, aggUser = userBucket1Buckets' }
, AggUserResult { aggUserTypeKey = bucket2Key, aggUser = userBucket2Buckets' }
]
)
parseAggUser :: Value -> Either String [AggUserResult]
parseAggUser = parseAgg aggUserParser
aggUserResult :: IO [AggUserResult]
aggUserResult = aggResult parseAggUser esAggUserFrontsAndBacks.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE QuasiQuotes, OverloadedStrings #-}
module FrontsAndBacks where
import GHC.Generics
import Control.Lens
import Control.Monad
import Control.Exception
import Control.Applicative
import Network.URI hiding (query)
import Data.Maybe
import Data.Either
import Data.List as DL
import Data.Text as DT
import Data.ByteString.Lazy
import Data.Aeson
import Data.Aeson.Types
import Database.SQLite.Simple
import Database.SQLite.Simple.FromRow
import NeatInterpolation as NI
import DB
import qualified FrontPageItems as FPI
import qualified HackerNewsItems as HNI
import qualified AlgoliaHits as AH
backsSqlSelectionString :: IO String
backsSqlSelectionString = fmap makeSqlString AH.algoliaHitsIdsFromUrlMatches
where
makeSqlString ids = DT.unpack $ [NI.text|
SELECT * FROM ${ahDbTableName} WHERE _id NOT IN (
SELECT _id FROM ${fpiDbTableName}
) AND url in (
SELECT url FROM ${ahDbTableName} GROUP BY url HAVING COUNT(url) > 1
) AND points <= 3
AND LENGTH(url) > 0
AND _id in (
SELECT ah._id FROM ${ahDbTableName} AS ah
INNER JOIN ${hniDbTableName} AS hni
ON ah.${hniDbTableName}Id = hni._id
WHERE ah.createdAt <= hni.time
)
AND _id IN (
${ids'}
)
AND ${hniDbTableName}Id NOT IN (
SELECT ah.${hniDbTableName}Id FROM ${ahDbTableName} AS ah
INNER JOIN ${hniDbTableName} AS hni ON ah.${hniDbTableName}Id = hni._id
WHERE ah._id != hni._id
AND ah.createdAt != hni.time
AND ah.points > 3
AND LENGTH(ah.url) > 0
)
|]
where
ids' = DT.pack $ DL.intercalate "," (Prelude.map show ids)
[ahDbTableName, hniDbTableName, fpiDbTableName] = Prelude.map DT.pack [
AH.dbTableName
, HNI.dbTableName
, FPI.dbTableName
]
getBacksInDb :: IO [AH.AlgoliaHit]
getBacksInDb = withConnection' queryForHits
where
queryForHits :: Connection -> IO [AH.AlgoliaHit]
queryForHits con = backsSqlSelectionString >>= (\ sql ->
query_ con (Query $ DT.pack (sql ++ ";"))
) :: IO [AH.AlgoliaHit]
getFrontsInDb :: IO [HNI.HackerNewsItem]
getFrontsInDb = withConnection' queryForItems
where
queryForItems :: Connection -> IO [HNI.HackerNewsItem]
queryForItems con = backsSqlSelectionString >>= (\ backSqlString ->
query_ con (Query $ makeSqlString $ DT.pack backSqlString )
)
makeSqlString backSqlString = [NI.text|
SELECT * FROM ${hniDbTableName} WHERE _id IN (
SELECT ${hniDbTableName}Id FROM (${backSqlString})
);
|]
where
hniDbTableName = DT.pack HNI.dbTableNameSentimentApi.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE DeriveGeneric, OverloadedStrings #-}
module SentimentApi where
import GHC.Generics
import Control.Lens hiding ((.=))
import Control.Monad
import Control.Exception
import Control.Applicative
import Network.URI hiding (query)
import Data.Maybe
import Data.Either
import Data.Text
import Data.ByteString.Lazy
import Data.Aeson
import Data.Aeson.Types
import Network.Wreq
-- https://github.com/mikelynn2/sentimentAPI
data SentimentApiResult = SentimentApiResult {
score :: Double
, result :: String
} deriving (Show, Generic)
instance FromJSON SentimentApiResult where
parseJSON (Object v) =
SentimentApiResult <$> v .: "score"
<*> v .: "result"
-- curl -H "Content-Type: application/json" -X POST -d '{"text":"text"}' http://127.0.0.1:8000/api/sentiment/v1
getSentimentApiResults :: [String] -> IO [SentimentApiResult]
getSentimentApiResults [] = return []
getSentimentApiResults (x:y) = fmap catMaybes (mapM getSentimentApiResult (x:y))
getSentimentApiResult :: String -> IO (Maybe SentimentApiResult)
getSentimentApiResult s = post apiUrl json >>= parseResponse
where
apiUrl = "http://localhost:8000/api/sentiment/v1"
json = object [ "text" .= (s :: String) ]
parseResponse :: Response ByteString -> IO (Maybe SentimentApiResult)
parseResponse r = return (decode (r ^. responseBody) :: Maybe SentimentApiResult)TimeAnalysis.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE OverloadedStrings #-}
module TimeAnalysis where
import GHC.Generics
import GHC.OldList as GOL
import Text.Printf
import Data.Maybe
import Data.List as DL
import Data.Default.Class
import Data.Colour
import Data.Colour.Names
import Graphics.Rendering.Chart
import Graphics.Rendering.Chart.Easy
import Graphics.Rendering.Chart.Backend.Cairo
import qualified Elasticsearch as ES
import qualified Common as CO
degreesOfFreedom :: Int -> Int -> Int
degreesOfFreedom rows cols = (rows - 1) * (cols - 1)
expectedFreq :: Integer -> Integer -> Integer -> Double
expectedFreq rowTotal tableTotal colTotal = (fromInteger rowTotal * fromInteger colTotal) / fromInteger tableTotal
expectedFreqs :: Integer -> Integer -> [Integer] -> [Double]
expectedFreqs _ _ [] = []
expectedFreqs rowTotal tableTotal colTotals = Prelude.map (expectedFreq rowTotal tableTotal) colTotals
chiSquare :: [(Integer, Double)] -> Double
chiSquare [] = -1.0
chiSquare (x:y) = Prelude.sum (
Prelude.map (\ (o, e) ->
((fromInteger o - e)**2.0) / e
) (x:y)
)
cramersV :: Integer -> Int -> Int -> Double -> (Double, Int)
cramersV n rows cols chi = ((chi / (fromIntegral n * fromIntegral df))**(1/2), df)
where
df = min (rows - 1) (cols - 1)
chiSquareHour :: IO (Double, Int)
chiSquareHour = chiSquareAgg (hoursList . ES.aggHour)
chiSquareDay :: IO (Double, Int)
chiSquareDay = chiSquareAgg (daysList . ES.aggDay)
chiSquareAgg :: (ES.AggDayHourResult -> [Integer]) -> IO (Double, Int)
chiSquareAgg f = do
aggDayHourResult <- ES.aggDayHourResult
if Prelude.length aggDayHourResult == 2
then do
let backs = f $ Prelude.head aggDayHourResult
let fronts = f $ Prelude.last aggDayHourResult
let rowTotals = [Prelude.sum backs, Prelude.sum fronts]
let colTotals = Prelude.zipWith (+) backs fronts
let tableTotal = Prelude.sum rowTotals
print tableTotal
print (Prelude.sum colTotals)
print rowTotals
let observed = backs ++ fronts
let backsExpected = expectedFreqs (Prelude.head rowTotals) tableTotal colTotals
let frontsExpected = expectedFreqs (Prelude.last rowTotals) tableTotal colTotals
printCountExpectedValueRow "Back" backs backsExpected
printCountExpectedValueRow "Front" fronts frontsExpected
print colTotals
let expected = backsExpected ++ frontsExpected
let expectedLtFive = Prelude.filter (< 5.0) expected
putStrLn $ "% Expected Values less than 5.0: " ++ show (100.0 * (
fromIntegral (Prelude.length expectedLtFive) / fromIntegral (Prelude.length expected)
))
let observedExpected = Prelude.zip observed expected
let numCols = Prelude.length colTotals
let numRows = Prelude.length rowTotals
let chi = chiSquare observedExpected
let dof = degreesOfFreedom numRows numCols
putStrLn $ "CramersV: " ++ show (cramersV tableTotal numRows numCols chi)
return (chi, dof)
else return (-1.0, 0)
where
printCountExpectedValueRow t c ev =
putStrLn $ t ++ "," ++ DL.intercalate "," (
Prelude.map (\(x,y) ->
show x ++ " (" ++ (Text.Printf.printf "%.2f" y :: String) ++ ")"
) $ Prelude.zip c ev
)
timeList :: Int -> [Integer] -> [(Integer, Integer)] -> [Integer]
timeList t _ [] = Prelude.take t [0, 0..]
timeList t r (x:y) = Prelude.map (\ a ->
maybe 0 snd (GOL.find ((== a) . fst) (x:y))
) r
daysList :: [(Integer, Integer)] -> [Integer]
daysList = timeList 7 [1..7]
hoursList :: [(Integer, Integer)] -> [Integer]
hoursList = timeList 24 [0..23]
backsDayAgg :: IO [(Integer, Integer)]
backsDayAgg = do
aggDayHourResult <- ES.aggDayHourResult
let backs = (daysList . ES.aggDay) $ Prelude.head aggDayHourResult
return (Prelude.zip [1..7] backs)
frontsDayAgg :: IO [(Integer, Integer)]
frontsDayAgg = do
aggDayHourResult <- ES.aggDayHourResult
let fronts = (daysList . ES.aggDay) $ Prelude.last aggDayHourResult
return (Prelude.zip [1..7] fronts)
chartDayAgg :: IO ()
chartDayAgg = do
backsDayAgg' <- backsDayAgg
frontsDayAgg' <- frontsDayAgg
let backsTotal = CO.secondSum backsDayAgg' :: Integer
let frontsTotal = CO.secondSum frontsDayAgg' :: Integer
let dow = ["Mon", "Tue", "Wed", "Thur", "Fri", "Sat", "Sun"]
let plotData = Prelude.map (
\ ((d, b), (_, f)) -> (dow!!fromInteger (d - 1), [
(fromInteger b / fromInteger backsTotal) :: Double
, (fromInteger f / fromInteger frontsTotal) :: Double
])
) $ Prelude.zip backsDayAgg' frontsDayAgg'
print $ Prelude.sum $ map (\ (_, b:f:_) -> b) plotData
print $ Prelude.sum $ map (\ (_, b:f:_) -> f) plotData
let plotDataDiff = Prelude.map (
\ (d, b:f:_) -> (d, [abs $ (f :: Double) - (b :: Double)])
) plotData
toFile (FileOptions (1500,1000) SVG) "./charts/chartDayAgg.svg" $ do
layout_title .= "Hacker News Fronts vs Backs - Days of the Week"
layout_y_axis . laxis_generate .= scaledAxis def (0.0, 0.2)
layout_x_axis . laxis_generate .= autoIndexAxis (map fst plotData)
setColors $ map opaque [lightskyblue, lightcoral]
plot $ plotBars <$> bars' ["Backs", "Fronts"] (addIndexes (map snd plotData))
toFile (FileOptions (1500,1000) SVG) "./charts/chartDayDiffAgg.svg" $ do
layout_title .= "Hacker News Fronts vs Backs - Days of the Week Difference"
layout_y_axis . laxis_generate .= scaledAxis def (0.0, 0.2)
layout_x_axis . laxis_generate .= autoIndexAxis (map fst plotDataDiff)
setColors $ map opaque [lightsteelblue]
plot $ plotBars <$> bars' ["|Fronts - Backs|"] (addIndexes (map snd plotDataDiff))
return ()
backsHourAgg :: IO [(Integer, Integer)]
backsHourAgg = do
aggDayHourResult <- ES.aggDayHourResult
let backs = (hoursList . ES.aggHour) $ Prelude.head aggDayHourResult
return (Prelude.zip [0..23] backs)
frontsHourAgg :: IO [(Integer, Integer)]
frontsHourAgg = do
aggDayHourResult <- ES.aggDayHourResult
let fronts = (hoursList . ES.aggHour) $ Prelude.last aggDayHourResult
return (Prelude.zip [0..23] fronts)
chartHourAgg :: IO ()
chartHourAgg = do
backsHourAgg' <- backsHourAgg
frontsHourAgg' <- frontsHourAgg
let backsTotal = CO.secondSum backsHourAgg' :: Integer
let frontsTotal = CO.secondSum frontsHourAgg' :: Integer
let hod = map (\ x -> show x ++ "00") [0..23]
let plotData = Prelude.map (
\ ((h, b), (_, f)) -> (hod!!fromInteger h, [
(fromInteger b / fromInteger backsTotal) :: Double
, (fromInteger f / fromInteger frontsTotal) :: Double
])
) $ Prelude.zip backsHourAgg' frontsHourAgg'
print $ Prelude.sum $ map (\ (_, b:f:_) -> b) plotData
print $ Prelude.sum $ map (\ (_, b:f:_) -> f) plotData
let plotDataDiff = Prelude.map (
\ (h, b:f:_) -> (h, [abs $ (f :: Double) - (b :: Double)])
) plotData
toFile (FileOptions (1500,1000) SVG) "./charts/chartHourAgg.svg" $ do
layout_title .= "Hacker News Fronts vs Backs - Hours of the Day"
layout_y_axis . laxis_generate .= scaledAxis def (0.0, 0.1)
layout_x_axis . laxis_generate .= autoIndexAxis (map fst plotData)
setColors $ map opaque [lightskyblue, lightcoral]
plot $ plotBars <$> bars' ["Backs", "Fronts"] (addIndexes (map snd plotData))
toFile (FileOptions (1500,1000) SVG) "./charts/chartHourDiffAgg.svg" $ do
layout_title .= "Hacker News Fronts vs Backs - Hours of the Day Difference"
layout_y_axis . laxis_generate .= scaledAxis def (0.0, 0.1)
layout_x_axis . laxis_generate .= autoIndexAxis (map fst plotDataDiff)
setColors $ map opaque [lightsteelblue]
plot $ plotBars <$> bars' ["|Fronts - Backs|"] (addIndexes (map snd plotDataDiff))
return ()
chartDayHourAgg :: IO ()
chartDayHourAgg = chartDayAgg >> chartHourAgg
-- Modified from
-- https://hackage.haskell.org/package/Chart-1.8/docs/src/Graphics-Rendering-Chart-Easy.html#bars
-- to remove borders.
bars' :: (PlotValue x, BarsPlotValue y) => [String] -> [(x,[y])] -> EC l (PlotBars x y)
bars' titles vals = liftEC $ do
styles <- sequence [fmap mkStyle takeColor | _ <- titles]
plot_bars_titles .= titles
plot_bars_values .= vals
plot_bars_style .= BarsClustered
plot_bars_spacing .= BarsFixGap 30 5
plot_bars_item_styles .= styles
where
mkStyle c = (solidFillStyle c, Nothing)TitleAnalysis.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE QuasiQuotes, OverloadedStrings #-}
module TitleAnalysis where
import System.Process
import Control.Monad
import Data.Maybe
import Data.List as DL
import Data.Map as DM
import Data.Set as DS
import Data.Text as DT
import qualified Data.ByteString.Lazy as DBL
import Data.Aeson
import NeatInterpolation as NI
import qualified HackerNewsItems as HNI
import qualified AlgoliaHits as AH
import qualified FrontsAndBacks as FOB
import qualified Elasticsearch as ES
import qualified SentimentApi as SA
import qualified Common as CO
esAggTitleResult :: IO ([(String, Integer)], [(String, Integer)])
esAggTitleResult = CO.esAggBackFrontFieldResult ES.aggTitle ES.aggTitleResult
corpusIO :: IO [String]
corpusIO = fmap corpus esAggTitleResult
corpus :: ([(String, Integer)], [(String, Integer)]) -> [String]
corpus (b, f) = DL.sort $ DS.toList $ DS.fromList $ Prelude.map fst (b ++ f :: [(String, Integer)])
backsAndFrontsTitles :: IO ([String],[String])
backsAndFrontsTitles = do
backsTitles <- fmap (Prelude.map AH.title) FOB.getBacksInDb
frontsTitles <- fmap (Prelude.map HNI.title) FOB.getFrontsInDb
return (backsTitles, frontsTitles)
chartTitleAgg :: IO ()
chartTitleAgg = do
(backs, fronts) <- esAggTitleResult
let backsTotal = CO.secondSum backs
let frontsTotal = CO.secondSum fronts
let backsMap = CO.makeKeyMap backsTotal backs
let frontsMap = CO.makeKeyMap frontsTotal fronts
let keys = corpus (backs, fronts)
let backsMap' = CO.makeAllKeyMap keys backsMap
let frontsMap' = CO.makeAllKeyMap keys frontsMap
let backsFronts = [
(k, [CO.lookupKey k backsMap', CO.lookupKey k frontsMap']) |
k <- keys, CO.lookupKey k frontsMap' >= 0.0
]
let tableString = DL.intercalate "\n" $ "Type Word Value":[
"Backs \""
++ k
++ "\" "
++ show b
++ "\nFronts \""
++ k
++ "\" "
++ show f
| (k, [b, f]) <- backsFronts
]
let tableFile = "./data/txt/chartTitleAggTable.txt"
writeFile tableFile tableString
let rfile = "./src/chartTitleAgg.r"
let chartFile = "./charts/chartTitleAgg.svg"
CO.writeROrPyFile makeRFile tableFile chartFile rfile
CO.runRFile rfile
return ()
where
makeRFile :: Text -> Text -> Text
makeRFile tableFile chartFile = [NI.text|
library(ggplot2);
data = read.table(file='${tableFile}', header=T);
p = ggplot(data, aes(reorder(factor(Word), Value), Value, fill=Type)) +
geom_bar(stat='identity', width=0.5, position=position_dodge(width=0.5)) +
coord_flip() +
scale_fill_manual(values=c('#87cefa', '#f08080')) +
labs(x='', y='', title='Hacker News Fronts vs Backs - Title Word Relative Frequency') +
theme(
legend.position='top',
legend.title=element_blank(),
plot.margin=unit(c(1,1,1,1), 'in'),
axis.text.y=element_text(size=12)
);
ggsave(filename='${chartFile}', plot=p, width=20, height=400, units='in', limitsize=F);
|]
chartSentimentAnalysis :: IO ()
chartSentimentAnalysis = do
(backsTitles, frontsTitles) <- backsAndFrontsTitles
backsSents <- sents backsTitles
frontsSents <- sents frontsTitles
let backsFronts = [("Backs", s) | s <- backsSents] ++ [("Fronts", s) | s <- frontsSents]
let tableString = DL.intercalate "\n" $ "Type Score":[
k
++ " "
++ show s
| (k, s) <- backsFronts
]
let tableFile = "./data/txt/chartTitleSentimentTable.txt"
writeFile tableFile tableString
let rfile = "./src/chartTitleSentiment.r"
let chartFile = "./charts/chartTitleSentiment.svg"
CO.writeROrPyFile makeRFile tableFile chartFile rfile
CO.runRFile rfile
return ()
where
sents :: [String] -> IO [Double]
sents t = fmap (Prelude.map SA.score) (SA.getSentimentApiResults t)
makeRFile :: Text -> Text -> Text
makeRFile tableFile chartFile = [NI.text|
library(ggplot2);
data = read.table(file='${tableFile}', header=T);
slice = data$$Type == 'Fronts'
data.fronts = data[slice,]$$Score
data.backs = data[!slice,]$$Score
t.test(data.fronts, data.backs)
p = ggplot(data, aes(x=factor(Type), y=Score), fill=factor(Type)) +
geom_boxplot(aes(fill=factor(Type)), outlier.colour='#ff00a2') +
geom_jitter() +
scale_fill_manual(values=c('#87cefa', '#f08080')) +
coord_flip() +
labs(
x='',
y='\nLinearSVC Confidence Score (Distance from Sample to Hyperplane)\n\n0 - Neutral, >0 - Positive, <0 - Negative',
title='Hacker News Fronts vs Backs - Title Sentiment'
) +
theme(
legend.position='top',
legend.title=element_blank(),
plot.margin=unit(c(1,1,1,1), 'in'),
axis.text.y=element_text(size=12)
);
ggsave(filename='${chartFile}', plot=p, width=20, height=20, units='in', limitsize=F);
|]
chartTitleProjection :: IO ()
chartTitleProjection = do
(backsTitles, frontsTitles) <- backsAndFrontsTitles
let json = encode $ object [ "fronts" .= backsTitles, "backs" .= frontsTitles ]
let jsonFile = "./data/json/chartTitleProjection.json"
DBL.writeFile jsonFile json
let chartFile = "./charts/chartTitleProjection"
let pyfile = "./venv/src/chartTitleProjection.py"
CO.writeROrPyFile makePyFile jsonFile chartFile pyfile
createProcess (proc "./venv/bin/python" [pyfile])
return ()
where
makePyFile :: Text -> Text -> Text
makePyFile jsonFile chartFile = [NI.text|
import json
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import axes3d
from sklearn.manifold import TSNE, MDS, LocallyLinearEmbedding
from sklearn.feature_extraction.text import TfidfVectorizer
with open('${jsonFile}') as f:
data = json.load(f)
tfidf = TfidfVectorizer(stop_words='english', strip_accents='unicode', norm=None)
tfidf.fit(data['backs'] + data['fronts'])
for projector in [MDS, TSNE, LocallyLinearEmbedding]:
for two_d in [True, False]:
backVecs = tfidf.transform(data['backs'])
frontVecs = tfidf.transform(data['fronts'])
n_components = 2 if two_d else 3
transBackVecs = projector(n_components=n_components).fit_transform(backVecs.toarray())
transFrontVecs = projector(n_components=n_components).fit_transform(frontVecs.toarray())
transBackVecs1 = []
transFrontVecs1 = []
for r in transFrontVecs:
transFrontVecs1.append(list(r) + ['Fronts'])
for r in transBackVecs:
transBackVecs1.append(list(r) + ['Backs'])
transBackFrontVecs = transBackVecs1 + transFrontVecs1
columns = ['x', 'y', 'Type'] if two_d else ['x', 'y', 'z', 'Type']
df = pd.DataFrame(transBackFrontVecs, columns=columns)
title = 'Hacker News Fronts vs Backs - Titles Projection ' + projector.__name__ + '\n'
if two_d:
sns.plt.clf()
sns.set_style('darkgrid')
sns.set_palette(sns.color_palette(['#87cefa', '#f08080']))
p = sns.lmplot(
x='x',
y='y',
data=df,
fit_reg=False,
hue='Type',
size=15,
markers=['o', 'p'],
scatter_kws={'s': 100, 'edgecolor': 'black', 'linewidth': 1.0}
)
p.fig.subplots_adjust(top=0.90, bottom=0.10, left=0.10, right=0.90)
chartFile = '${chartFile}' + projector.__name__ + '.svg'
sns.plt.title(
title,
fontsize=20
)
sns.plt.savefig(chartFile)
else:
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1, axisbg='1.0')
ax = fig.gca(projection='3d')
for coords, color in [(transBackVecs1, '#87cefa'), (transFrontVecs1, '#f08080')]:
df = pd.DataFrame(coords, columns=columns)
ax.scatter(df['x'].tolist(), df['y'].tolist(), df['z'].tolist(), color=color)
plt.title(title)
plt.legend(loc=2)
plt.show()
print('Done.')
|]UserAnalysis.hs
{-
David Lettier (C) 2016
http://www.lettier.com/
-}
{-# LANGUAGE QuasiQuotes, OverloadedStrings #-}
module UserAnalysis where
import System.Process
import Control.Monad
import Data.Maybe
import Data.List as DL
import Data.Map as DM
import Data.Set as DS
import Data.Text as DT
import qualified Data.ByteString.Lazy as DBL
import Data.Aeson
import NeatInterpolation as NI
import qualified HackerNewsItems as HNI
import qualified AlgoliaHits as AH
import qualified FrontsAndBacks as FOB
import qualified Elasticsearch as ES
import qualified SentimentApi as SA
import qualified Common as CO
esAggUserResult :: IO ([(String, Integer)], [(String, Integer)])
esAggUserResult = CO.esAggBackFrontFieldResult ES.aggUser ES.aggUserResult
corpusIO :: IO [String]
corpusIO = fmap corpus esAggUserResult
corpus :: ([(String, Integer)], [(String, Integer)]) -> [String]
corpus (b, f) = DL.sort $ DS.toList $ DS.fromList $ Prelude.map fst (b ++ f :: [(String, Integer)])
chartUserAgg :: IO ()
chartUserAgg = do
(backs, fronts) <- esAggUserResult
let backsTotal = CO.secondSum backs
let frontsTotal = CO.secondSum fronts
let backsMap = CO.makeKeyMap backsTotal backs
let frontsMap = CO.makeKeyMap frontsTotal fronts
let keys = corpus (backs, fronts)
let backsMap' = CO.makeAllKeyMap keys backsMap
let frontsMap' = CO.makeAllKeyMap keys frontsMap
let backsFronts = [
(k, [CO.lookupKey k backsMap', CO.lookupKey k frontsMap']) |
k <- keys, CO.lookupKey k frontsMap' >= 0.0
]
let tableString = DL.intercalate "\n" $ "Type User Value":[
"Backs \""
++ k
++ "\" "
++ show b
++ "\nFronts \""
++ k
++ "\" "
++ show f
| (k, [b, f]) <- backsFronts
]
let tableFile = "./data/txt/chartUserAggTable.txt"
writeFile tableFile tableString
let rfile = "./src/chartUserAgg.r"
let chartFile = "./charts/chartUserAgg.svg"
CO.writeROrPyFile makeRFile tableFile chartFile rfile
CO.runRFile rfile
return ()
where
makeRFile :: Text -> Text -> Text
makeRFile tableFile chartFile = [NI.text|
library(ggplot2);
data = read.table(file='${tableFile}', header=T);
p = ggplot(data, aes(reorder(factor(User), Value), Value, fill=Type)) +
geom_bar(stat='identity', width=0.5, position=position_dodge(width=0.5)) +
coord_flip() +
scale_fill_manual(values=c('#87cefa', '#f08080')) +
labs(x='', y='', title='Hacker News Fronts vs Backs - User Relative Frequency') +
theme(
legend.position='top',
legend.title=element_blank(),
plot.margin=unit(c(1,1,1,1), 'in'),
axis.text.y=element_text(size=12)
);
ggsave(filename='${chartFile}', plot=p, width=20, height=150, units='in', limitsize=F);
|]